Poster as presented at Psychonomics 2000
(Return to Scharff Research Summary page.)
Many perceptual stimuli are cross-modal, processed by more than one sensory modality. Human perceptual processing tends to interpret covarying visual and auditory information as originating from one stimulus event, and this interpretation is adaptive for organizing or guiding one's perceptions. Researchers of cross-modal perception traditionally have chosen static stimuli over dynamic stimuli. Further, horizontal or vertical placements have been chosen over placements in depth. Most of these experiments present stimuli via two-dimensional computer screens, thus it is difficult to create three-dimensional stimuli. It can be argued that two-dimensional experimental conditions are somewhat restricted in ecological validity and generalizability to the natural world.
The lack of dynamic conditions also limits generalizability. Introducing dynamic conditions leads to considerations of representational momentum, which is a memory distortion in thedirection of anticipated change for the final position or magnitude of a dynamic stimulus (e.g., Freyd, 1987; Freyd & Johnson, 1987). Representational momentum has been shown for auditory pitch (Freyd, Kelly, & DeKay, 1990; Hubbard, 1993; Hubbard, 1995a; Kelly & Freyd, 1987), as well as for motion of stimuli in perceived depth, represented as size change on a two-dimensional screen (Kelly &Freyd, 1987, Hubbard, 1995b; Hubbard, 1995c).
Perceptual interactions between various auditory-visual, cross-modal stimuli were investigated in the present study. In addition to the standard conditions with high and low tones paired with high and low vertical positions, the present work incorporated conditions with frequency glides (dynamic) and stereoscopic depth.
The present study included two static, cross-modal and two dynamic, cross-modal experiments. The first static, cross-modal experiment was a partial replication of Ben-Artzi and Marks (1995), using high-low tones and high-low vertical positions of visual stimuli. The second static, cross-modal experiment used the same tones paired with near-far positions of visual depth stimuli. The two dynamic, cross-modal experiments used the same visual stimuli conditions, pairing them with ascending-descending frequency glides.The resulting combinations are referred to as: vertical-tone (VT), vertical-glide (VG), depth-tone (DT) and depth-glide (DG). For each dimension, there were two possible ranges, small and large. A further contribution of the current study was the addition of auditory reference tones
Previous research provided neither visual nor auditory fixation points prior to each trial (Ben-Artzi & Marks, 1995; Melara & O'Brien, 1987). However, it can be argued that the computer screen itself acted as a frame of reference for the visual stimuli. Thus, their findings that visual stimuli more strongly interfered with the classification of auditory stimuli partially may have been due to the lack of an auditory frame of reference. The addition of the reference tones led to a doubling of the experimental sessions, so that there were eight total cross-modal experiments.
As with previous cross-modal research, the present study used four levels of predictability: baseline, positively-correlated, negatively-correlated, and orthogonal (Ben-Artzi & Marks,1995). In the baseline condition, the participants knew the physical dimension to be classified, and this was the only dimension that varied. In the two correlated conditions, the two dimensions varied together either positively (e.g., high/high and low/low) or negatively (e.g., high/low and low/high), i.e., the values on each dimension always perfectly predicted one another. In the correlated conditions, the speed of response tends to be faster and accuracy of response higher, representative of more efficient processing (Bernstein & Edelstein, 1971; Marks, 1987; Melara, 1989; Melara & O'Brien, 1987). The improved performance on correlated conditions is defined as redundancy gain (Ben-Artzi & Marks,1995; Melara & O'Brien, 1987). Lastly, in the orthogonal condition, positively-correlated and negatively-correlated trials were randomly interleaved in the same experiment. Orthogonal variation in the irrelevant dimensions shows Garner interference, leading to lower accuracy and slower reaction times compared to baseline (Ben-Artzi & Marks, 1995; Melara & O'Brien, 1987).
Eight participants individually completed four one-hour sessions. Four of the participants were designated as having "less" musical experience, with zero to three years of formal training on a musical instrument, and four were designated as having "more" musical experience, with six to 15 years of formal training on a musical instrument.
Visual-auditory stimuli were presented in a darkened, acoustically-dampened room on a computer screen via a front-mirror stereoscopic apparatus. Participants were instructed to work asaccurately and as quickly as possible. Before each block of conditions, the participant was shown instructions on the screen that explained which modality to classify and which task to expect in that block (VT, VG, DT, DG). In contrast to previous studies (e.g., Ben-Artzi & Marks, 1995, Melara & Marks, 1987), participants were not explicitly instructed to ignore the irrelevant dimension. After reading the instructions, the participant was given a practice session of 8 trials.
Two stimuli (a left eye's view and a right eye's view), created the image of a single black square on a white screen. For the vertical conditions, perception of a single square "high" or "low" onthe screen was achieved when the two squares were both presented a certain distance above or below (but at the same depth as) the placewhere a nonius fixation cross had just disappeared. For the depthconditions, the square appeared to be closer to or farther from theviewer's perception of the place where the nonius fixation cross hadjust disappeared. Depth was created by shifting the right eye's viewrelative to the left eye's view.
For all trials, participants fused the nonius fixation and initiated the presentation of the stimuli. When no reference tone waspresented, the trial began with a 500 ms auditory stimulus, which was immediately followed by presentation of the visual stimulus for 250ms. A blank screen then appeared and remained until the participantresponded. As soon as a key press response was made, there was ablank screen for another 500 ms, and then the nonius fixation for thenext trial appeared. For the experiments with reference tones, theprocedure was identical except that immediately prior to the auditory stimulus, a 250 ms reference tone was presented during a blank screen, followed by a 250 ms pause (See Figure 1). It was not possible to present the auditory and visual stimuli concurrently; therefore, the auditory stimulus was always presented first because echoic memory (~3-4 s) is longer than iconic memory (~0.25 s).
The four experimental sessions (auditory classification with /without tones and visual classification with / without tones) were blocked and completely counterbalanced across participants. Within each session, task (VT, VG, DT, DG) was blocked and completely counterbalanced across participants, and within each task, predictability (baseline, positive, negative, orthogonal) was blocked and counterbalanced. Within each predictability block, range combinations were randomized. Keyboard responses were also counterbalanced across participants.
Statistical analyses were carried out on the data of six of the eight participants. One of the participants excluded showed an uncharacteristic practice effect. The other participant showed an uncharacteristically high error rate that seems to have been due to confusion about how to indicate his responses across the different conditions. Reaction time analyses used only correct responses, and conditions were required to have above-chance likelihood. Accuracy analyses were based on the number of correct responses per condition.
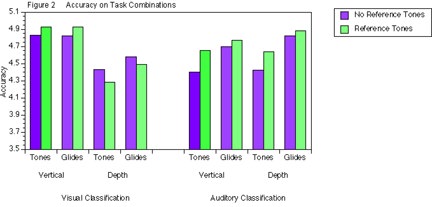
As shown in Figure 2, accuracy was improved when reference tones were present, especially for auditory classification. A significant interaction between Task and Classification, F(3, 15) = 4.17, p <.025, showed that for visual classification, vertical classifications were more accurate than depth classifications. For auditory classification, tone classifications were more accurate than glide classifications.
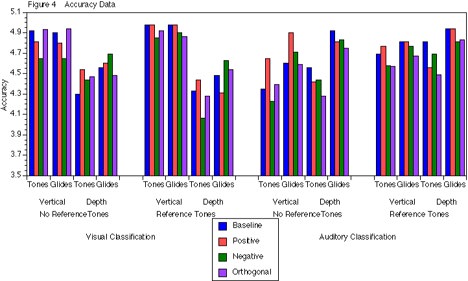
Figure 3 illustrates accuracy as a function of Classification (visual and auditory),Task (VT, VG, DT, DG), and Predictability (baseline, positive, negative, orthogonal). Separate analyses were done for Reference (without reference tones or with reference tones), although the findings were similar. There were significant interactions between Classification and Task, (F(3, 15) = 3.46, p< .05 and F(3, 15) = 3.42, p < .05, respectively). These interactions were also illustrated in Figure 2. Predictability did not affect accuracy as hypothesized.
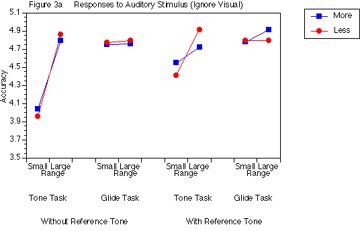
Figure 4a illustrates accuracy as a function of Auditory Task (tones and glides), Range (small and large), and Music Training (more and less). This was analyzed separately for conditions with and without reference tones. Without reference tones, there was a significant interaction between Range and Auditory Stimulus, F(1, 4)= 9.95, p < .05, such that the large range improved accuracy for tones, but glides showed high accuracy for both the small and large ranges. The main effects for Task and Range were also significant, (F(1, 4) = 21.23, p < .01 and F(1, 4) = 8.58, p < .05,respectively). With reference tones, there were no significant effects, although there was a tendency for the large range to be more accurate than the small range. Importantly, the addition of the reference tones increased the accuracy of the small range when classifying tones, relative to the trials without reference tones. Surprisingly, music training seemed to have little influence on accuracy for the auditory tasks.
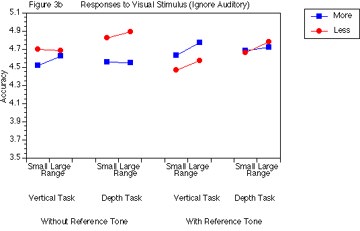
Figure 4b illustrates accuracy as a function of Visual Task (vertical and depth), Range (small and large), and Music Training (more and less). Without reference tones, the main effect for Range approached significance, with a tendency for the large range to be more accurate than the small range. A significant three-way interaction, F(1, 4) = 10.80, p < .05, showed that the less musically-trained participants were more accurate than the more musically-trained participants on both the vertical and the depth conditions, with a larger difference for the depth task. With reference tones, there were no significant effects, and the addition of reference tones did not have an apparent effect on accuracy. However, the more musically-trained participants were more accurate on vertical conditions than the less musically-trained participants, and there was no difference between the two groups on the depth conditions.
Upon reflection, a possible dynamic effect for the visual stimuli became apparent, especially for the vertical conditions. For some participants the visual stimuli may have had implied motion. That is, there may have been a phi effect between the visual fixation stimulus and the visual stimulus that immediately followed. This effect may explain some of the present study's findings of residual differences in accuracy between visual and auditory classification, even when using reference tones.
The possibility that people's use of semantic labels affects their performance is an issue of cross-modal research. Redundant semantic labels may lead to more cross-modal conflict. For example, vertical positions and tones have a redundant, cross-modal semantic correlate (e.g., a "high" position and a "high" pitch). In the current research, the depth positions and glide directions lack comparable semantic correlates, which may have led to the reduced cross-modal conflict.
Due to the small number of participants in this study, power was quite low. The post-hoc analyses of music training had even less power. Thus, a larger sample size would benefit future research and allow investigation of various experience effects, such as music training and prior experience with visual depth.
This research was supported in part by Stephen F. Austin State University Faculty Research Grant #1-14111.